Google出品的6个AI黑科技
1、 RewNeRF
Google 的 RawNeRF 是一个基于人工智能的工具,可以对图像进行智能降噪点,同时还可以改变其拍摄角度、焦点、曝光水平和色调映射,而且上述所有这些都可以在照片拍摄后再进行调整。简单来说,就是一款可以将2D图片变成3D的AI,它可以直接给照片经行3D建模。


原版 NeRF 使用色调映射的低动态范围 LDR 图像作为输入,而谷歌将 NeRF 修改为直接在线性原始图像上进行训练,保留场景的完整动态范围,可以有效地将 RawNeRF 变成一个多图像降噪器,能够组合来自数十或数百个输入图像的信息。

除了改变相机视角之外,RawNeRF 可以在后期调整焦点、曝光和色调映射,也就是像图片中演示的那样。
2、 MusicLM
MusicLM,能以24kHz的采样率产生高质量的音乐,在数分钟内保持一致,同时忠实于给定的文本输入。这个模型是由谷歌研究团队在最近的一篇论文中提出的,它的目的是协助音乐家和作曲家完成创造性的音乐任务。本文将探讨MusicLM的技术细节和它的能力,以及它的优势、局限性和潜在应用。
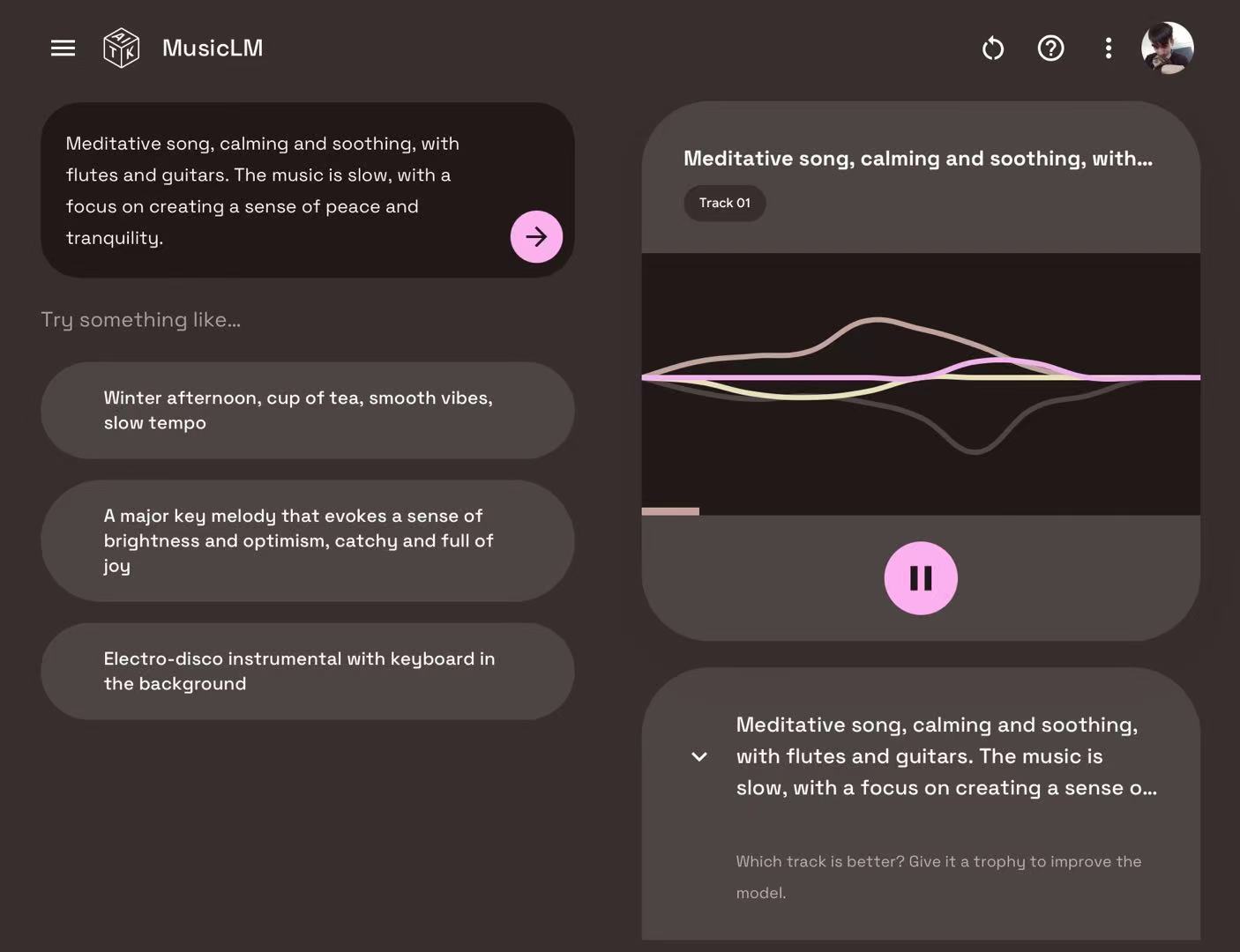
MusicLM通过数十万小时的音频进行训练,学习在多种风格中创作新音乐,现已通过Google的AI Test Kitchen应用进行预览。
在Test Kitchen中使用MusicLM非常直观。一旦你获得访问权限,你将看到一个文本框,你可以在其中输入歌曲描述——细致入微也好,粗略一瞥也罢——然后让系统生成两个版本的歌曲。两个版本都可以下载进行离线收听,但Google鼓励你对其中一首歌曲进行“点赞”,以帮助提高AI的性能。
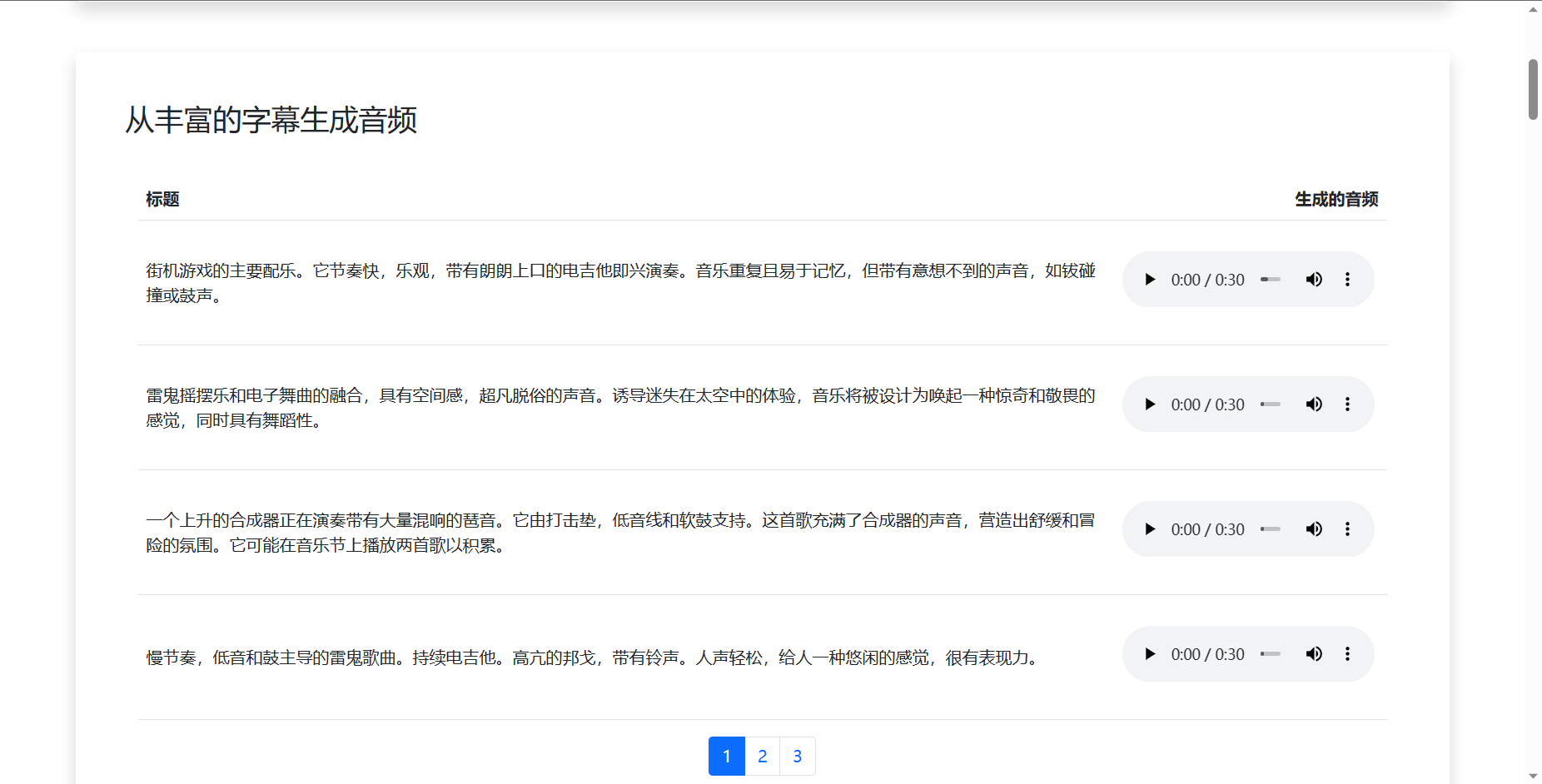
它还拥有通过图片来作曲的能力。
总的来说,MusicLM比几年前OpenAI尝试创建的AI音乐生成器Jukebox做得要好得多。与MusicLM相比,只要给出一种音乐类型,一位艺术家和一段歌词片段,Jukebox就能生成相对连贯的音乐,并配有人声,但是Jukebox产生的歌曲缺乏像重复的合唱这样的典型音乐元素,而且经常包含无意义的歌词。MusicLM生成的歌曲也包含较少的人工元素,总的来说,在保真度方面感觉是一个升级。
3、 Wordcraft
Wordcraft是一个由AI驱动的创意写作助手。 Wordcraft仅需少量样本学习和对话,就能提供各种用户交互,支持各种故事写作任务,还可以帮助作家规划故事大纲、写作和编辑。
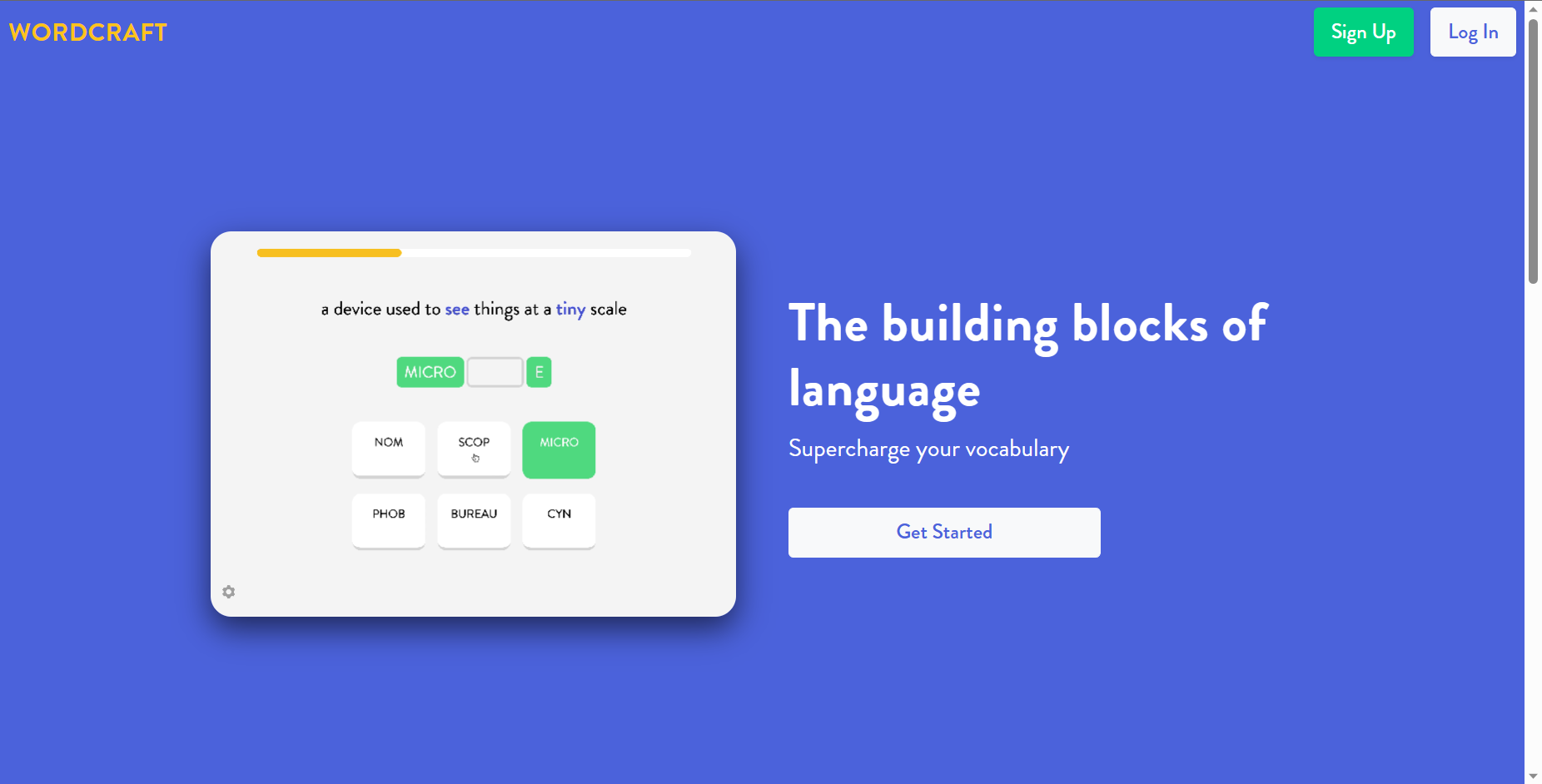
Wordcraft基于 LaMDA(对话应用程序语言模型),这是一种由 Google 开发的语言模型,能够生成文本并维护对话。如果这个 AI 不能真正理解语言、含义或上下文,它知道如何生成看起来像人类的语音,这要归功于它所训练的无数数据。
然而,Wordcraft 工具与它所依赖的 AI 不同。Mountain View 公司解释说,它类似于一种混合了在线文字处理器的“文本编辑器”。例如,用户可以要求它改写句子,使句子更有趣,甚至描述对象。它不会生成故事,而是根据作者的要求向作者提供想法。
4、 Dramatron
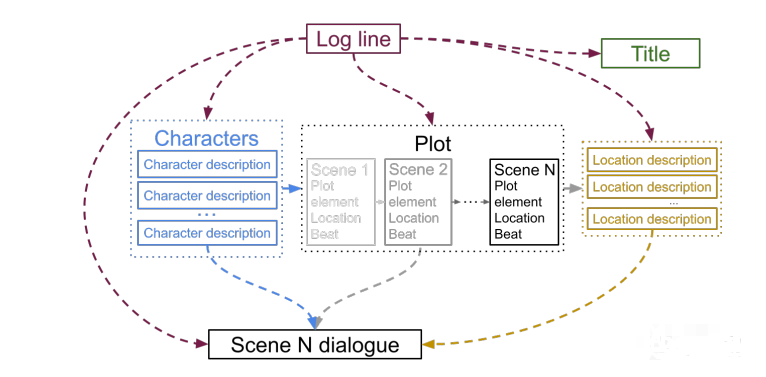
Dramatron 是一个所谓的「联合写作」工具,你给它一句话(log line)描述中心戏剧冲突(比如 James 在有 Sam 鬼魂出没的后院发现了一口井),它就能自动写出标题、角色、场景描述和对话。
使用Dramatron创作剧本,人们只需要在模型中输入Log Line(故事的一句话摘要。之后,Dramatron就会自动生成剧本标题、人物以及场景设定、细节和对话。
和很多生成式 AI 工具一样,Dramatron 的背后也有一个大型语言模型作为支撑。这个模型名为 Chinchilla,参数量为 70B,在 1.4T token 的 MassiveText 数据集上进行训练。不过,DeepMind 在论文中表示,OpenAI 的 GPT-3 等大模型也可以用来部署 Dramatron。
可以说,Dramatron 和 ChatGPT 很像,但它的输出更容易被改写成电影脚本。
5、 Muse
谷歌公开了一款名为 “Muse” 的基于文本生成图像的模型,声称可以实现最先进的图像生成性能。它生成的图片画质高清、效果自然,只要输入一句文字描述它就可以马上生成图片。

文本到图像生成是 2022 年最火的 AIGC 方向之一,被《science》评选为 2022 年度十大科学突破。最近,谷歌的一篇文本到图像生成新论文《Muse: Text-To-Image Generation via Masked Generative Transformers》又引起高度关注。
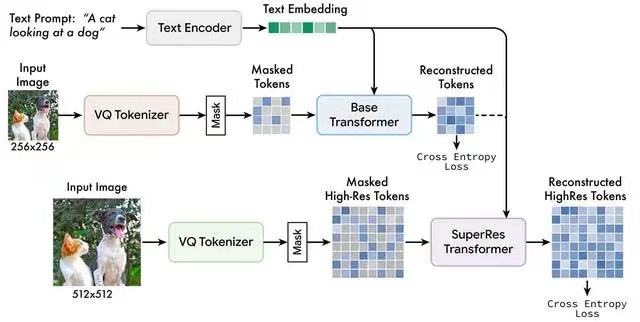
文本 – 图像生成:Muse 模型从文本提示快速生成高质量的图像(在 TPUv4 上,对于 512×512 分辨率的图像需要时间为 1.3 秒,生成 256×256 分辨率的图像需要时间为 0.5 秒)。例如生成「一只熊骑着自行车,一只鸟栖息在车把上。

Muse 还提供了基于掩码的编辑,例如「在美丽的秋叶映照下,有一座凉亭在湖上」。

6、Phenaki
Phenaki 是 Google Research 的一个项目,其目标是从开放域的文本描述中合成逼真的视频。Phenaki 这个名字可能来源于费纳奇镜(Phenakistiscope),一种19世纪发明的早期动画装置。
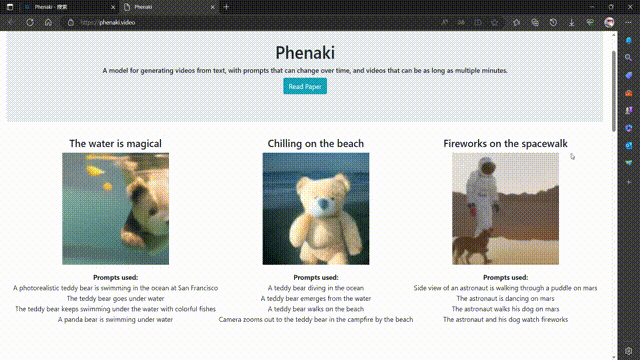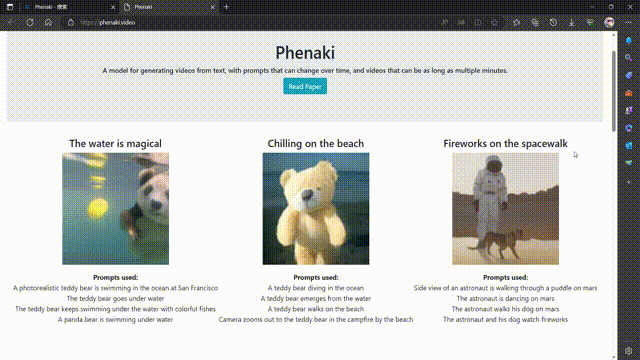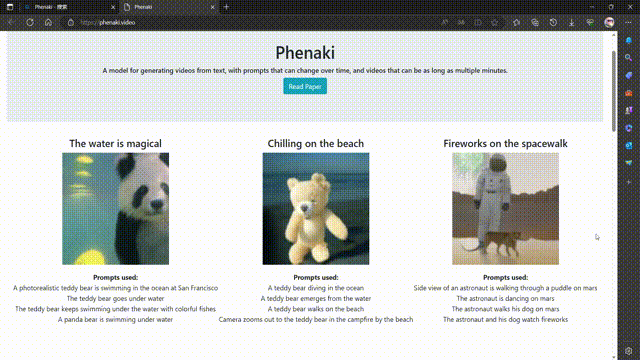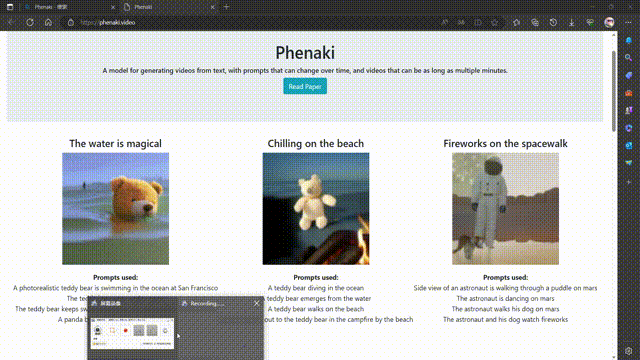
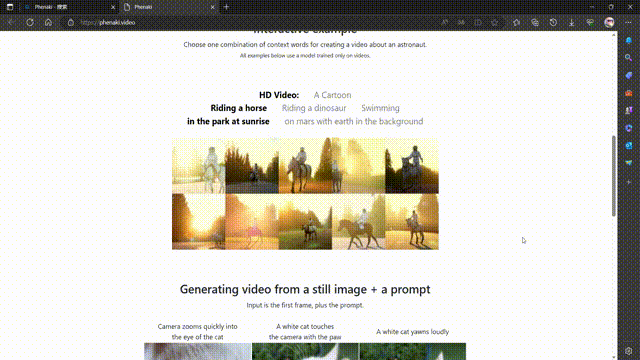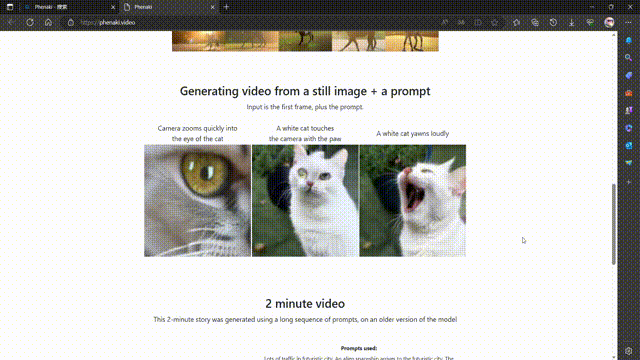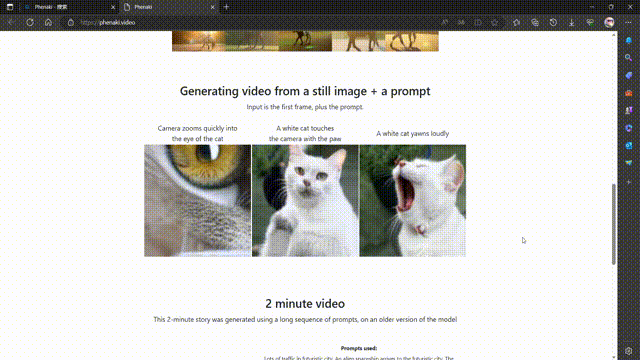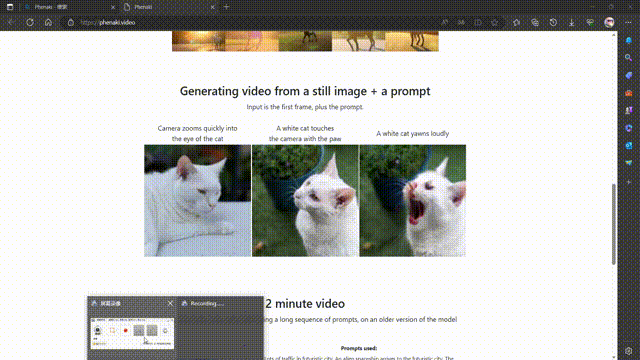
Phenaki 的核心是两个主要组件:一个编码器-解码器模型,用于将视频压缩为离散的嵌入或令牌(token),以及一个变换器模型,用于将文本嵌入转换为视频令牌1。这样,用户只需输入一段或多段文本提示,就可以让 Phenaki 生成相应的视频令牌,并将其解码为实际的视频。
关于我们
请关注公众号:AI超级智库
公众号将作为AIGC超级智库的官网入口,发布行业最新学习资料、资讯,请一定要关注
社群
进入AIGC交流学习群,大家一起交流学习,希望大家共同努力,维护高质量交流社群!请加微信
同时请遵守群规,营造一个好的学习环境,严禁广告、引流、政治、TZ等敏感话题,必飞机✈️

相关文章

 京公网安备 11010802039477号
京公网安备 11010802039477号